-
파이썬 통계분석_Chapter01. 데이터카테고리 없음 2024. 1. 11. 16:28
데이터의 개념과 통계 분석에서 사용하는 기본적인 용어 및 데이터 분류


Pandas의 read_csv 함수를 사용하면 csv파일을 읽어들일 수 있다.
이 때, 데이터는 Pandas의 DataFrame이라는 데이터 구조로 반환한다.
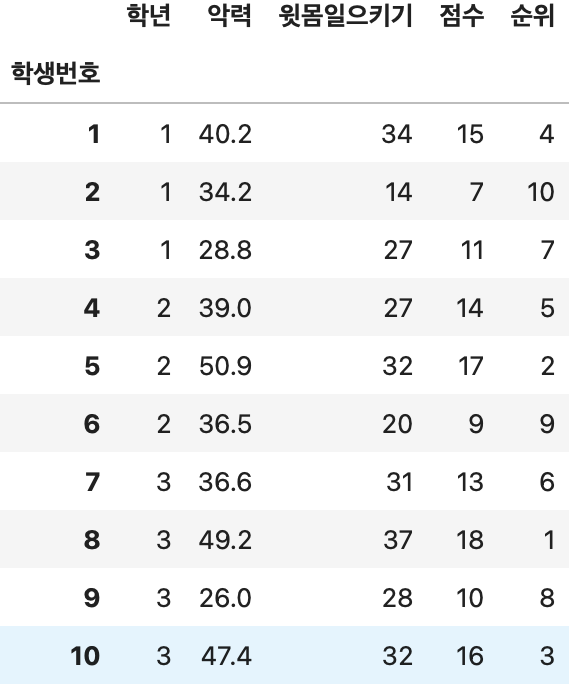
DataFrame에서 이름을 지정하여 하나의 열만도 추출할 수 있다.


이 때, 반환되는 것은 DataFrame이 아니라 Series구조이다.
** DataFrame : 2차원 표 데이터 구조
** Series : 1차원 데이터 구조

데이터의 크기는 shape이라는 인스턴스 변수를 참조해 알 수 있다.

일반적으로 shape을 참조하면 2개의 수가 출력된다.
첫 번째 수가 데이터에 대한 수이고 두 번째 수가 변수에 대한 수이다.
# DB라면 각각 레코드 수, 칼럼 수이다.
변수는 학년이나 악력같은 측정 대상을 가리킨다.
이 데이터에서 5개의 변수가 있으므로 5변수 또는 5차원이라고 한다.
변수는 성질에 따라 다양하게 분류가 가능하고 크게 질적 변수와 양적 변수로 분류할 수 있다.
질적 변수는 명의 척도와 순서 척도, 양적 변수는 간격 척도와 비례 척도로 더욱 세분화되고 이 네가지를 척도 수준이라 한다.
- 질적 변수는 선택이 필요나 변수나 종류를 구별하기 위한 변수를 말한다.
ex) 남성/여성, 흡연 여부 -> 값이 2개뿐인 질적 변수는 2진변수
01. 명의 척도 : 단순히 분류를 하기 위한 변수
변수의 동일성 여부만 확인
ex) 학생 번호, 전화 번호, 성별
02. 순서 척도 : 순서 관계나 대소 관계에 의미가 있는 변수
ex) 성적 순위, 설문 조사의 만족도
- 양적 변수는 양을 표현하는 변수를 말한다.
03. 간격 척도 : 대소 관계와 함께 그 차이에도 의미를 두는 변수
ex) 연도, 온도
04. 비례 척도 : 대소 관계, 차이, 비 모두에 의미가 있는 변수
ex) 길이, 무게
** 간격 척도와 비례 척도의 구별은 0의 의미를 확인 -> 0이 없음을 의미한다면 비례 척도
변수를 질적/양적 변수가 아니라 이산형, 연속형 변수로 나누어 분류도 가능하다.
이산형 변수는 0,1,2,...과 같이 하나하나의 값을 취하는 변수
연속형 변수는 연속적인 값을 취할 수 있는 변수로, 어떤 두 숫자 사이에도 반드시 숫자가 존재하는 것.
ex) 길이, 무게, 시간
누구나 파이썬 통계분석 [티나아이 히로키] 참고